3.10 Chemical Reactions in Living Things

Created by: CK-12/Adapted by Christine Miller
Assembly Line
We stay alive because millions of different chemical reactions are taking place inside our bodies all the time. Each of our cells is like the busy auto assembly line pictured in Figure 3.10.1. Raw materials, half-finished products, and waste materials are constantly being used, produced, transported, and excreted. The “workers” on the cellular assembly line are mainly enzymes. These are the proteins that make biochemical reactions happen.
What Are Biochemical Reactions?
Chemical reactions that take place inside living things are called biochemical reactions. The sum of all the biochemical reactions in an organism is called metabolism. Metabolism includes both exothermic (energy-releasing) chemical reactions and endothermic (energy-absorbing) chemical reactions.
Catabolic Reactions
Exothermic reactions in organisms are called catabolic reactions. These reactions break down molecules into smaller units and release energy. An example of a catabolic reaction is the breakdown of glucose during cellular respiration, which releases energy that cells need to carry out life processes.
Anabolic Reactions
Endothermic reactions in organisms are called anabolic reactions. These reactions build up bigger molecules from smaller ones and absorb energy. An example of an anabolic reaction is the joining of amino acids to form a protein. Which type of reactions — catabolic or anabolic — do you think occur when your body digests food?
Enzymes
Most of the biochemical reactions that happen inside of living organisms require help. Why is this the case? For one thing, temperatures inside living things are usually too low for biochemical reactions to occur quickly enough to maintain life. The concentrations of reactants may also be too low for them to come together and react. Where do the biochemical reactions get the help they need to proceed? From the enzymes.
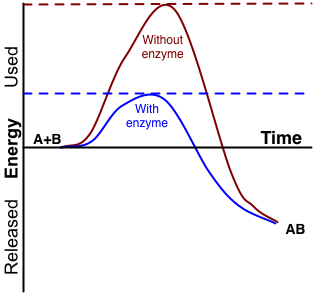
An enzyme is a protein that speeds up a biochemical reaction. It is a biological catalyst. An enzyme generally works by reducing the amount of activation energy needed to start the reaction. The graph in Figure 3.10.2 shows the activation energy needed for glucose to combine with oxygen. Less activation energy is needed when the correct enzyme is present than when it is not present.
An enzyme speeds up the reaction by lowering the required activation energy. Compare the activation energy needed with and without the enzyme.
How Well Enzymes Work
Enzymes are involved in most biochemical reactions, and they do their jobs extremely well. A typical biochemical reaction that would take several days or even several centuries to happen without an enzyme is likely to occur in just a split second with the proper enzyme! Without enzymes to speed up biochemical reactions, most organisms could not survive.
Enzymes are substrate-specific. The substrate of an enzyme is the specific substance it affects. Each enzyme works only with a particular substrate, which explains why there are so many different enzymes. In addition, for an enzyme to work, it requires specific conditions, such as the right temperature and pH. Some enzymes work best under acidic conditions, for example, while others work best in neutral environments.
Enzyme-Deficiency Disorders
There are hundreds of known inherited metabolic disorders in humans. In most of them, a single enzyme is either not produced by the body at all, or is otherwise produced in a form that doesn’t work. The missing or defective enzyme is like an absentee worker on the cell’s assembly line. Imagine the auto assembly line from the image at the start of this section. What if the worker who installed the steering wheel was absent? How would this impact the overall functioning of the vehicle? When an enzyme is missing, toxic chemicals build up, or an essential product isn’t made. Generally, the normal enzyme is missing because the individual with the disorder inherited two copies of a gene mutation, which may have originated many generations previously.
Any given inherited metabolic disorder is generally quite rare in the general population. However, there are so many different metabolic disorders that a total of one in 1,000 to 2,500 newborns can be expected to have one.
3.10 Summary
- Biochemical reactions are chemical reactions that take place inside of living things. The sum of all of the biochemical reactions in an organism is called metabolism.
- Metabolism includes catabolic reactions, which are energy-releasing (exothermic) reactions, as well as anabolic reactions, which are energy-absorbing (endothermic) reactions.
- Most biochemical reactions need a biological catalyst called an enzyme to speed up the reaction. Enzymes reduce the amount of activation energy needed for the reaction to begin. Most enzymes are proteins that affect just one specific substance, which is called the enzyme’s substrate.
- There are many inherited metabolic disorders in humans. Most of them are caused by a single defective or missing enzyme.
3.10 Review Questions
- What are biochemical reactions?
- Define metabolism.
- Compare and contrast catabolic and anabolic reactions.
- Explain the role of enzymes in biochemical reactions.
- What are enzyme-deficiency disorders?
- Explain why the relatively low temperature of living things, along with the low concentration of reactants, would cause biochemical reactions to occur very slowly in the body without enzymes.
- Answer the following questions about what happens after you eat a sandwich.
- Pieces of the sandwich go into your stomach, where there are digestive enzymes that break down the food. Which type of metabolic reaction is this? Explain your answer.
- During the process of digestion, some of the sandwich is broken down into glucose, which is then further broken down to release energy that your cells can use. Is this an exothermic endothermic reaction? Explain your answer.
- The proteins in the cheese, meat, and bread in the sandwich are broken down into their component amino acids. Then your body uses those amino acids to build new proteins. Which kind of metabolic reaction is represented by the building of these new proteins? Explain your answer.
- Explain why your body doesn’t just use one or two enzymes for all of its biochemical reactions.
- A ________ is the specific substance that an enzyme affects in a biochemical reaction.
- An enzyme is a biological _____________ .
- catabolism
- form of activation energy
- catalyst
- reactant
3.10 Explore More
Enzymes (Updated), by The Amoeba Sisters, 2016.
What triggers a chemical reaction? – Kareem Jarrah, TED-Ed, 2015.
Figure 3.10.1
Auto Assembly line by Brian Snelson on Wikimedia Commons is used under a CC BY 2.0 (https://creativecommons.org/licenses/by/2.0) license.
Figure 3.10.2
Enzyme_activation_energy by G. Andruk [IMeowbot at the English language Wikipedia], is used under a CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0/) license.
References
Amoeba Sisters. (2016, August 28). Enzymes (updated). YouTube. https://www.youtube.com/watch?v=qgVFkRn8f10&feature=youtu.be
TED-Ed. (2015, January 15). What triggers a chemical reaction? – Kareem Jarrah. YouTube. https://www.youtube.com/watch?v=8m6RtOpqvtU&feature=youtu.be
A chemical reaction is a process that leads to the chemical transformation of one set of chemical substances to another.
The smallest unit of life, consisting of at least a membrane, cytoplasm, and genetic material.
A class of biological molecule consisting of linked monomers of amino acids and which are the most versatile macromolecules in living systems and serve crucial functions in essentially all biological processes.
The transformation of one molecule to a different molecule inside a cell.
The chemical processes that occur in a living organism to sustain life.
A chemical reaction that releases energy through light or heat.
A type of metabolic reaction that takes place within a cell in which larger molecules are separated to form smaller molecules.
Anabolic reactions are endergonic, meaning they require an input of energy to progress and are not spontaneous. They involve creation of larger molecules from smaller units.
The ability to do work.
Amino acids are organic compounds that combine to form proteins.
Biological molecules that lower amount the energy required for a reaction to occur.
A substance that increases the rate of a chemical reaction without itself undergoing any permanent chemical change.
The minimum energy required to cause a reaction to occur.
A specific reactant in a chemical reaction which works with a specific enzyme.

{kind=link}
{kind=link}