5.6 Genetic Code
Created by: CK-12/Adapted by Christine Miller

Can You Code?
If someone asks you whether you can code, you probably assume they are referring to computer code. The image in Figure 5.6.1 represents an important code that you use all the time — but not with a computer! It’s the genetic code, and it is used by your cells to store information, as well as to make RNA and proteins.
What Is the Genetic Code?
The genetic code consists of the sequence of nitrogen bases in a polynucleotide chain of DNA or RNA. The bases are adenine (A), cytosine (C), guanine (G), and thymine (T) (or uracil, U, in RNA). The four bases make up the “letters” of the genetic code. The letters are combined in groups of three to form code “words,” called codons. Each codon stands for (encodes) one amino acid, unless it codes for a start or stop signal. There are 20 common amino acids in proteins. With four bases forming three-base codons, there are 64 possible codons. This is more than enough to code for the 20 amino acids. The genetic code is shown in Figure 5.6.2.
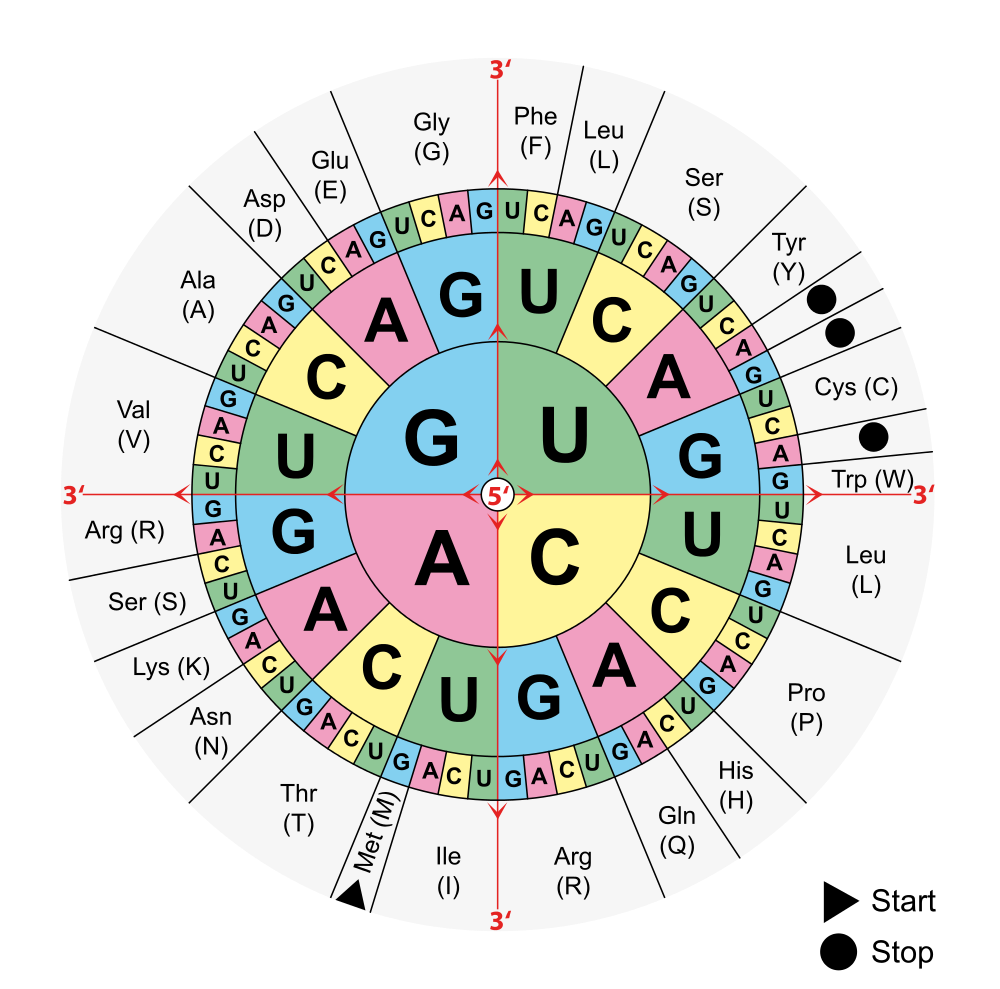
To find the amino acid for a particular codon, find the first base in the codon in the centre of the circle in Figure 5.6.2, then the second base in the middle row out from the center, and finally the third base in the outer ring For example, CUG codes for leucine, AAG codes for lysine, and GGG codes for glycine. Try it out: Can you figure out what the codon AGC codes for?
Reading the Genetic Code
If you find the codon AUG in Figure 5.6.2, you will see that it codes for the amino acid methionine. This codon is also the start codon that establishes the reading frame of the code. The start codon is a necessary tool in translation, since a single chromosome contains many genes. In order to transcribe and translate a gene for a specific protein, we need to know where in the DNA code to start “reading” the instructions. AUG signals the start of a reading frame. After the AUG start codon, the next three bases are read as the second codon. The next three bases after that are read as the third codon, and so on. The sequence of bases is read, codon by codon, until a stop codon is reached. UAG, UGA, and UAA are all stop codons. They do not code for any amino acids.
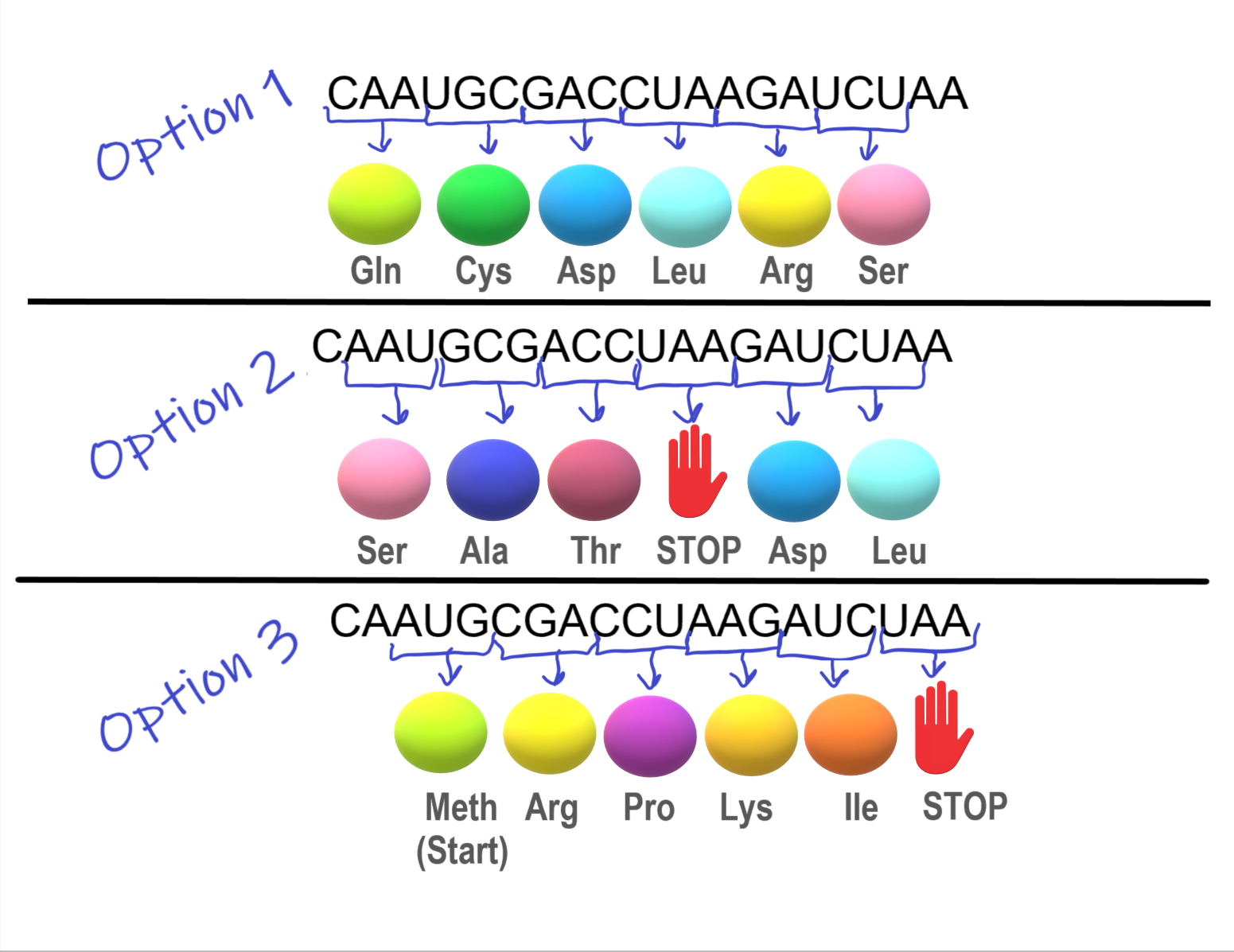
The importance of the reading frame is illustrated in the hypothetical situation below:
The section of mRNA in Figure 5.6.3 is designed to create a chain of five specific amino acids.
- In Option 1, a string of amino acids is created, but the chain does not have a stop codon, and so keeps on adding amino acids. This means the desired protein was not made.
- In Option 2, a stop codon was encountered and the amino acid chain was stopped after 3 amino acids. This means the desired protein was not made
- In Option 3, using the AUG start codon, a chain of five specific amino acids was successfully formed. Success! This was only possible because the start codon, AUG, specified the reading frame.
Characteristics of the Genetic Code
The genetic code has a number of important characteristics:
- The genetic code is universal. All known living things have the same genetic code, which shows that all organisms share a common evolutionary history.
- The genetic code is unambiguous. This means that each codon codes for just one amino acid (or start or stop). This is necessary so there is no question about which amino acid is correct.
- The genetic code is redundant. This means that each amino acid is encoded by more than one codon. For example, in Figure 5.6.2, four codons code for the amino acid threonine. Redundancy in the code helps prevent errors in protein synthesis. If a base in a codon changes by accident, there is a good chance that it will still code for the same amino acid.
Cracking the Code
The double helix structure of DNA was discovered in 1953. It took just eight more years to crack the genetic code. The scientist primarily responsible for deciphering the code was American biochemist Marshall Nirenberg, who worked at the National Institutes of Health in the United States. When Nirenberg began the research in 1959, the manner in which proteins are synthesized in cells was not well understood, and messenger RNA had not yet been discovered. At that time, scientists didn’t even know whether DNA or RNA was the molecule used as a template for protein synthesis. Nirenberg, along with a collaborator named Heinrich Matthaei, devised an ingenious experiment to determine which molecule — DNA or RNA — has this important role. They also began deciphering the genetic code.
Nirenberg and Matthaei added the contents of bacterial cells to each of 20 test tubes. The cell contents provided the necessary “machinery” for the synthesis of a polypeptide molecule. The researchers also added all 20 amino acids to the test tubes, with a different amino acid “tagged” by a radioactive element in each test tube. That way, if a polypeptide formed in a test tube, they would be able to tell which amino acid it contained. Then, they added synthetic RNA containing just one nitrogen base to all 20 test tubes. They used the base uracil in their first experiment. They discovered that an RNA chain consisting only of uracil bases produces a polypeptide chain of the amino acid phenylalanine. This experiment showed that RNA (rather than DNA) is the template for protein synthesis, but it also showed that a sequence of uracil bases codes for the amino acid phenylalanine. The year was 1961, and it was a momentous occasion. When Nirenberg presented the discovery at a scientific conference later that year, he received a standing ovation. As Nirenberg puts it, “…for the next five years I became like a scientific rock star.”
After Nirenberg and Matthaei cracked the first word of the genetic code, they used similar experiments to show that each codon consists of three bases. Before long, they had discovered the codons for all 20 amino acids. In 1968, in recognition of this important achievement, Nirenberg was named a co-winner of the Nobel Prize in Physiology or Medicine.
5.6 Summary
- The genetic code consists of the sequence of nitrogen bases in a polynucleotide chain of DNA or RNA. The four bases make up the “letters” of the code. The letters are combined in groups of three to form code “words” known as codons, each of which encodes for one amino acid or a start or stop signal.
- AUG is the start codon, and it establishes the reading frame of the code. After the start codon, the next three bases are read as the second codon, the three bases after that as the third codon, and so on until a stop codon is reached.
- The genetic code is universal, unambiguous, and redundant.
- The genetic code was cracked in the 1960s, mainly by a series of ingenious experiments carried out by Marshall Nirenberg, who won a Nobel Prize for this achievement.
5.6 Review Questions
- Describe the genetic code and explain how it is “read”
- Identify three important characteristics of the genetic code.
- Summarize how the genetic code was deciphered.
- Use the decoder above to answer the following questions:
- Is the code from DNA or RNA? How do you know?
- Which amino acid does the codon CAA code for?
- What does UGA code for?
- Look at the codons that code for the amino acid glycine. How many of them are there and how are they similar and different?
-
5.6 Explore More
Comparing DNA Sequences, Bozeman Science, 2012.
How to Read a Codon Chart, Amoeba Sisters, 2019.
Attributions
Figure 5.6.1
AMY1gene by unknown author from National Science Foundation on Wikimedia Commons is released into the public domain (https://en.wikipedia.org/wiki/Public_domain).
Figure 5.6.2
Aminoacids table (Adapted) by Mouagip on Wikimedia Commons is released into the public domain. (Original: Codons sun (“codesonne” in German) by Onie~commonswiki])
Figure 5.6.3
Reading Frame (3 Options) by Christine Miller is used under a CC BY-NC-SA 4.0 (https://creativecommons.org/licenses/by-nc-sa/4.0/) license.
References
Amoeba Sisters. (2019, September 17). How to read a codon chart. YouTube. https://www.youtube.com/watch?v=LsEYgwuP6ko&feature=youtu.be
Bozeman Science. (2012, September 15). Comparing DNA sequences. YouTube. https://www.youtube.com/watch?v=OSKwuOccAak&feature=youtu.be
Wikipedia contributors. (2020, July 2). Marshall Warren Nirenberg. In Wikipedia. https://en.wikipedia.org/w/index.php?title=Marshall_Warren_Nirenberg&oldid=965562106
The smallest unit of life, consisting of at least a membrane, cytoplasm, and genetic material.
A nucleic acid of which many different kinds are now known, including messenger RNA, transfer RNA and ribosomal RNA.
A sequence of 3 DNA or RNA nucleotides that corresponds with a specific amino acid or stop signal during protein synthesis.
Amino acids are organic compounds that combine to form proteins.
The specific location in DNA where a set of codons will code for a certain protein. The reading frame begins with the start codon (AUG).
Deoxyribonucleic acid - the molecule carrying genetic instructions for the development, functioning, growth and reproduction of all known organisms and many viruses.
A large family of RNA molecules that convey genetic information from DNA to the ribosome, where they specify the amino acid sequence of the protein products of gene expression.
The process of creating protein molecules.

{kind=link}
{kind=link}